


雲端自動擴展的隱患:配置錯誤將引爆成本危機?
在雲端時代,企業可透過各種雲端平台(如 AWS、Azure、GCP)快速部署與擴展服務。快速彈性擴充帶來的好處,也隱含了大量設定與資安管理上的挑戰。其中,Azure 平台提供了多項服務,包含 Azure VMSS(Virtual Machine Scale Sets) 、Azure App Service 等,都能協助企業以自動化的方式動態擴增或縮減資源。然而,若缺乏良好的配置,可能衍生出嚴重的系統風險與成本損失。
本案例將探討因「雲端主機組態設定錯誤」特別強調 Azure 環境下的自動化部署與 Scale Out/Scale In 風險。期望透過分析此事件脈絡,提醒企業在導入 Azure VMSS、Azure App Service 等服務時,應如何避免類似的管理疏失(在 CDN 等外部資源已進行適當的配置情境下)。
案例背景
企業簡介與系統現況
本案例的主角為一間中型軟體開發公司,主要業務為代管客戶的應用服務,並提供 SaaS 平台。該公司主要使用 Azure 作為雲端運算基礎,包括:
● Azure VMSS(Virtual Machine Scale Sets) :用於自動化部署並彈性調整多台虛擬機器,以因應流量波動。
● Azure App Service:提供 PaaS 形式的應用程式託管服務,開發團隊可快速上架與更新 Web 或 API。
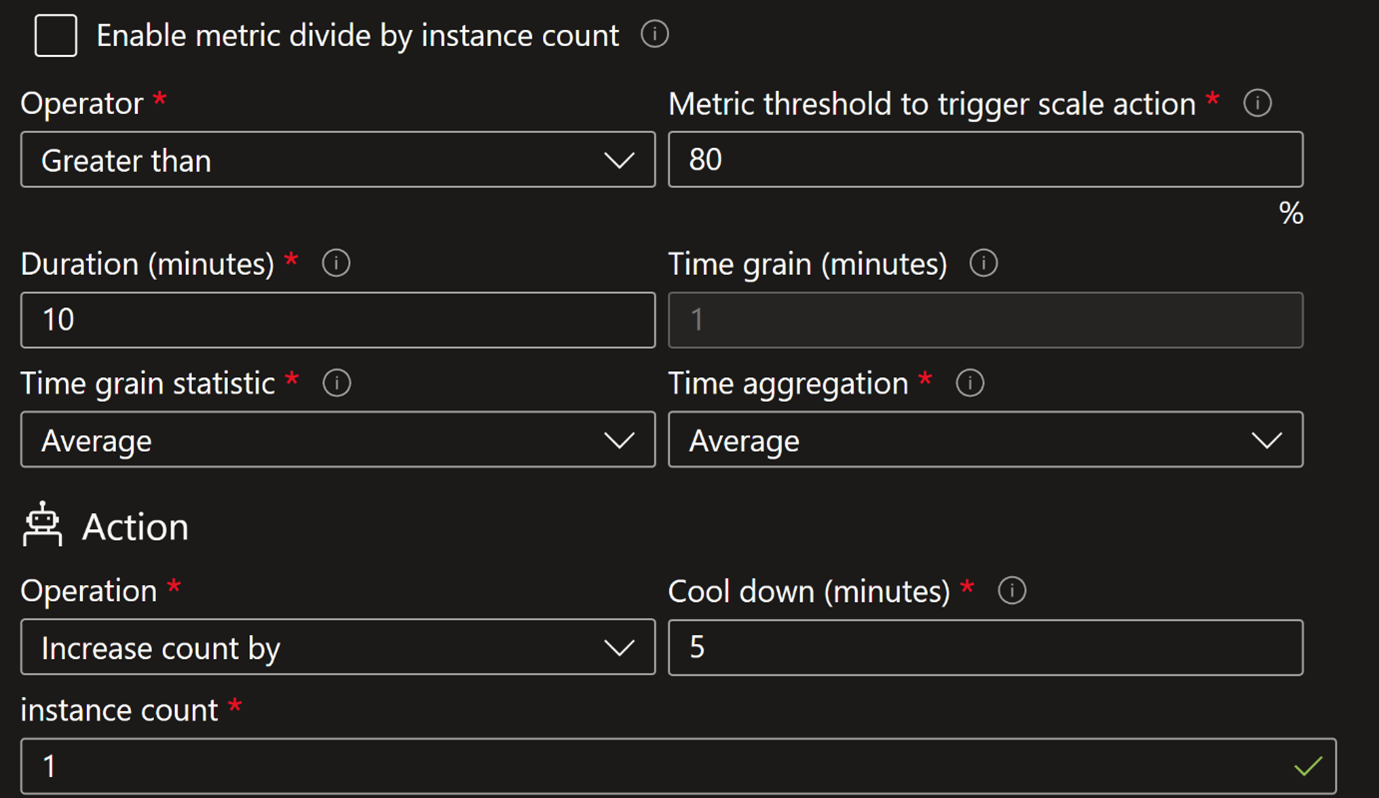
圖1、Azure VMSS AutoScaling配置Scale_out
由於近年來業務需求快速成長,該公司在 Azure 中同時使用多項服務的自動擴展功能(Scale Out)來應付高峰流量。然而,因為人力與管理流程不足,並沒有做好 「Scale In」(自動收斂)與安全性維護,導致系統配置信息凌亂。
某日,財務部門發現當期的 Azure 帳單費用較前一個月暴增好幾倍。資安團隊深入分析後,驚覺在 Azure VMSS 上有多台虛擬機器長期處於高負載;深入檢查後發現,因為某一次的突發請求(包含了正常與非正常服務請求),觸發了 Scale Out 卻沒有對應的自動收斂機制(Scale In),讓 VM 一直處於過量供應狀態,產生高昂的計算與網路傳輸成本。
在更深入調查後,公司發現了幾個問題癥結:
● 監控指標單一:大部分自動化擴展只依賴 CPU 或記憶體使用率做判斷,沒有綜合考量其他維度(例如請求數量、佇列長度等),導致流量暫時平穩後依然維持高規模資源。
● 未設定適當上限與下限:系統僅設定了「最大可擴展實例數(Max)」,卻忘了細調最小可縮容的實例數(Min),使得部分環境始終保有大量資源。
● 缺乏預算警示與花費監控:公司對於雲端花費沒有設定足夠的預算警示或自動化報表機制,導致費用暴增數週後才被發現。
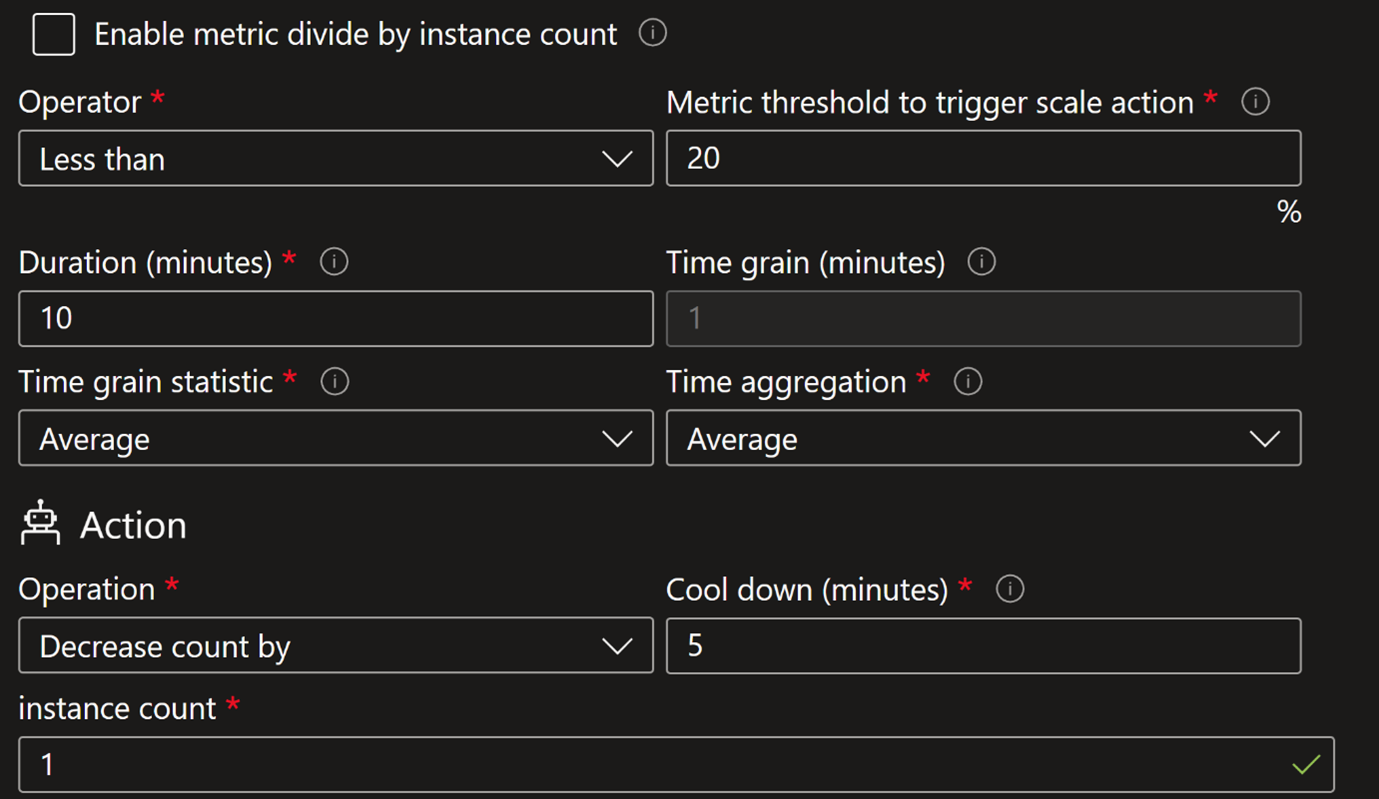
圖2、Azure VMSS AutoScaling配置Scale_In
Azure 自動化擴展機制與設定失誤解析
Azure VMSS AutoScaling 配置:單一指標觸發 Scale Out,VMSS 預設以 CPU 使用率大於 70% 超過 5 分鐘作為指標,就會生成新 VM;然而流量回落後,並未設定在 CPU 使用率低於 30% 時自動 Scale In 收回虛擬機器 。多個 VM 雖然在低負載狀況下處於 Idle 狀態,但仍持續計費造成成本浪費。
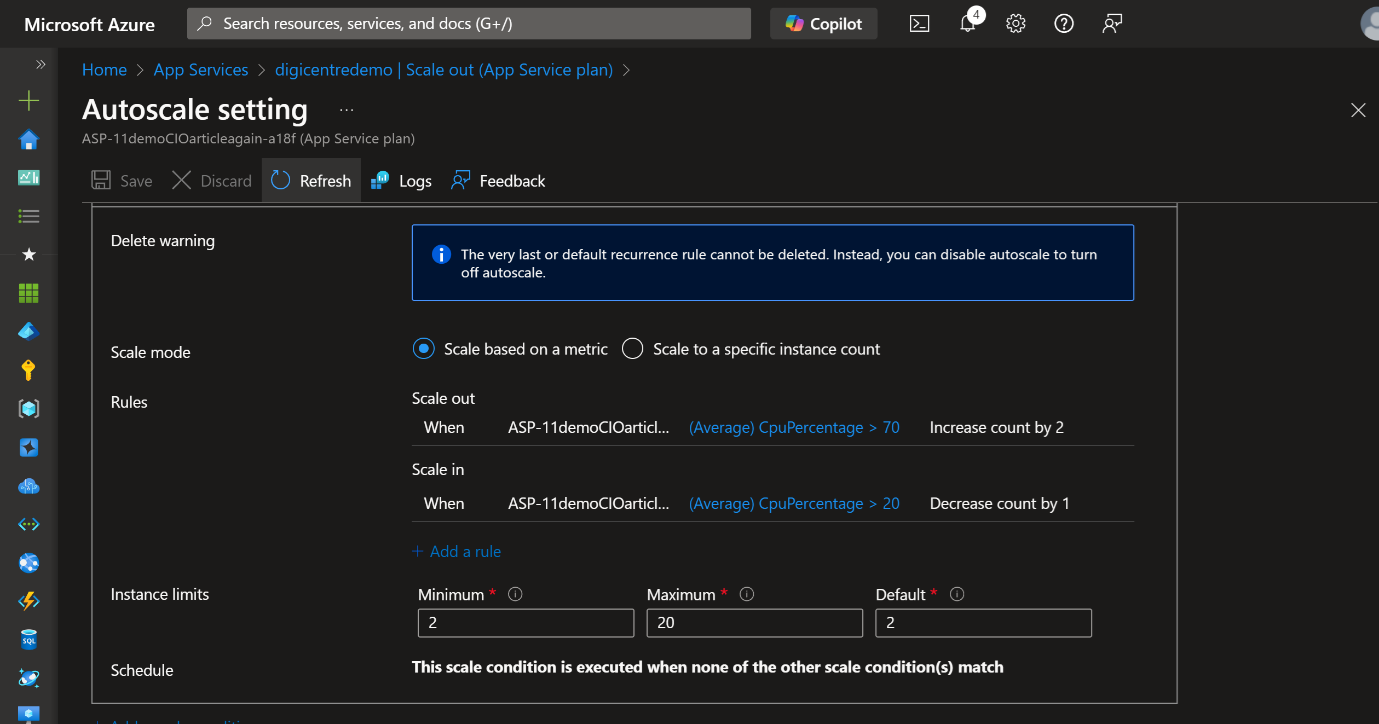
圖3、Azure App service Autoscaling配置-含自動收斂(scale in)
Azure App Service Autoscaling 配置:App Service Plan 多實例維持,當高峰結束後,背景工作(Background Jobs)偶爾佔用到 CPU 資源,導致無法觸發 Scale In 條件,長期保留數個多實例;Plan 層級升級後未降級:App Service Plan 在應對大流量時升級至更高層級,但缺乏持續監控機制,自動降級又不易,導致維持在昂貴的 Plan 上。
影響與損失評估
● 雲端服務費用激增:由於未正確設定 Scale In 策略,導致多個閒置虛擬機器或容器節點長期運作。App Service 保留在高階計費方案。流量傳輸費用也持續偏高。這些因素疊加在一起,讓公司於該月 Azure 帳單驟然提升,已超出原先預算好幾倍。
● 資源供應過剩與維運浪費:除了金錢花費外,也包括不必要的管理維護負擔,團隊需要追蹤與維護過多的運算資源或節點,增加操作複雜度。系統設計面混亂,由於許多臨時擴充的資源未被自動釋放,配置與映像檔版本也未統一更新。
● 錯誤需求判斷:當團隊看到「系統不斷有大量資源在跑」,可能誤以為是真實的用戶需求,進一步導致錯誤的商業決策(例如再購買更多預付型訂閱方案、長期租用大型 VM SKU)。
雲端主機正確配置與管理的重要性
● 定期檢視擴展與收斂配置:檢視觸發條件,確保 Scale Out、Scale In 的指標設定合理,不僅依賴 CPU,還能綜合考慮請求數、延遲、Memory、Queue 長度等。
● 設定上限與下限:同時要明確定義「最小與最大」的實例數量,避免無限制擴展或「無法」縮容。
● 監控與警示:用 Azure Monitor 或 Application Insights,設定警示(Alerts)當實例數量或費用超過門檻時即通知團隊。
● 最佳實務:多重指標與動態門檻(動態門檻 Dynamic Threshold),透過機器學習或歷史趨勢來調整閾值,避免單純設定固定 CPU% 數值。
● 結合應用層監控:除了系統層面,也要監控應用執行狀況,例如每秒交易量(TPS)、HTTP 狀態碼分佈等,才能精準判斷擴縮需求。
防範與應變建議
預防措施
● 建立雲端管理 SOP:明確規範自動擴展與收斂的設定流程、指標、與檢查週期。制定對應的測試計畫,於新專案或新功能上線前先檢驗擴縮策略,正確配置 App Service、VMSS。
● 引入預算與費用管理機制:在 Azure Cost Management 中設定警戒線與報表排程(見圖4)。定期(例如每週)召開成本檢討會議,及早發現異常。 應變流程
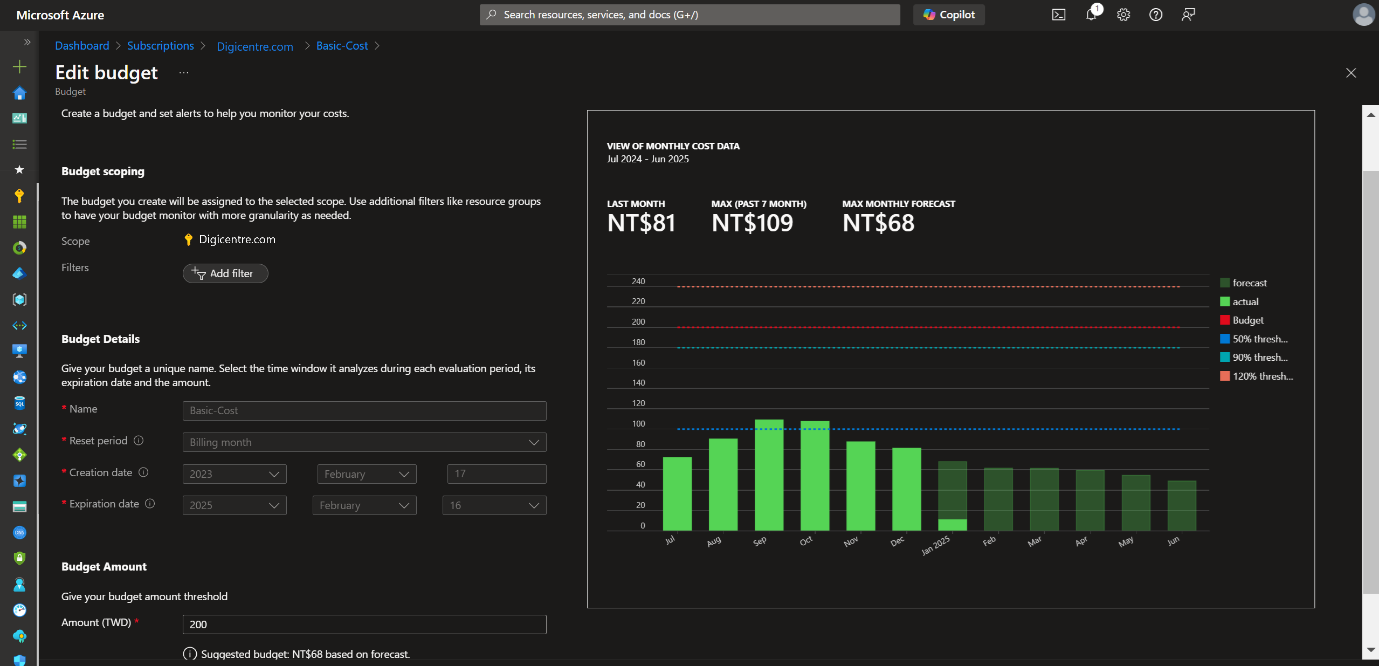
圖4、Azure配置費用告警
● 即時調整 Scale In 配置:若發現資源數量明顯超出實際需求(見圖5),先手動調整實例數量至合理範圍,並更新自動化規則。
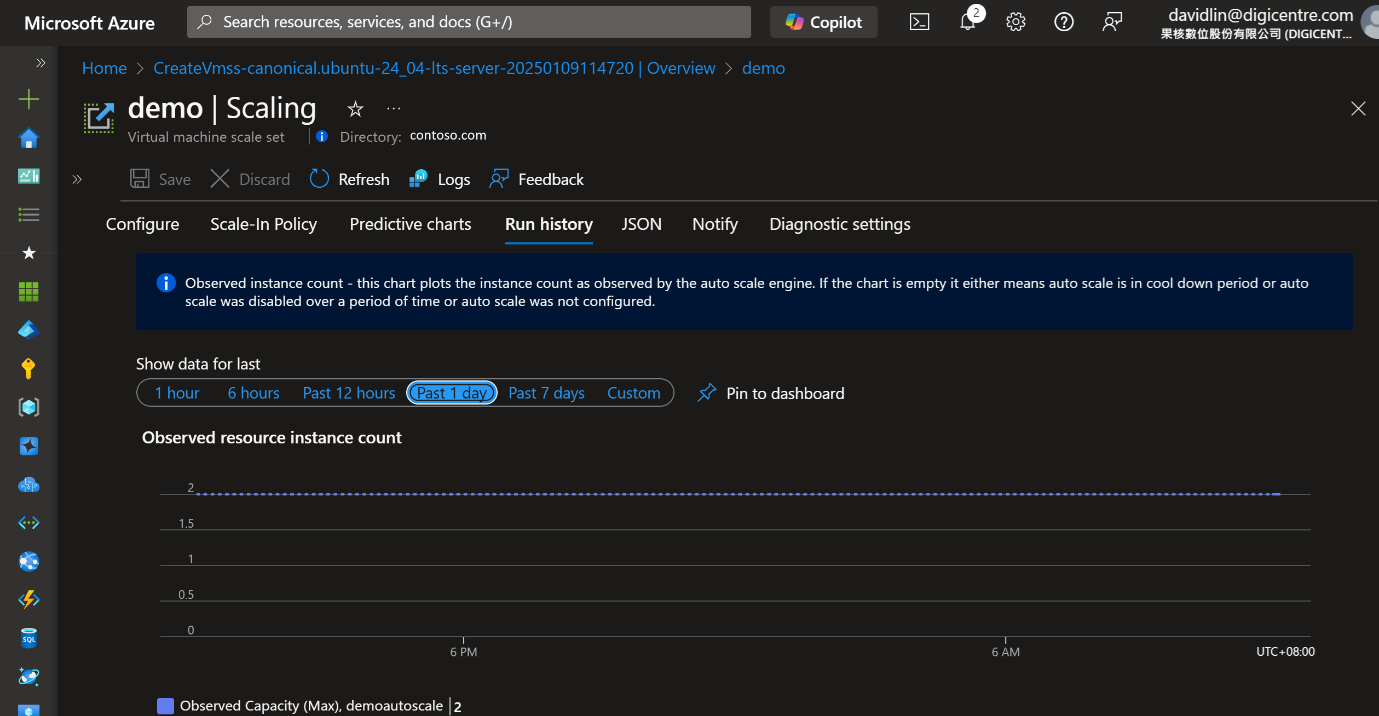
圖5、AutoScaling配置Status
● 教育訓練與團隊合作:雲端資源管理並非純技術問題,同時需要跨部門的財務預算觀念與資安意識。
● 財務部:可協助監控帳單和雲端消費異常。
● IT/運維部門:負責設定與維護自動化規則。
● 研發部門:需要瞭解自動擴展觸發機制(見圖6),撰寫程式時儘量避免過度持續占用系統資源。
圖6、AutoScaling配置Notify
在 CIO Taiwan 官網閱讀全文 : 雲端自動擴展的隱患:配置錯誤將引爆成本危機? https://www.cio.com.tw/85994/